
Event-driven AI automation patterns are architectural designs that trigger AI agent actions in direct response to discrete business events, replacing scheduled polling with real-time, condition-based processing. Where traditional automation waits for a clock, event-driven systems react the moment something meaningful happens: a transaction flags as anomalous, a customer submits a form, or a sensor breaches a threshold. Technologies like Google Cloud's BigQuery, Pub/Sub, and Vertex AI Agents already demonstrate this at production scale, and the pattern is now central to any credible digital transformation strategy. For IT decision-makers, understanding these patterns is the difference between building systems that scale and inheriting ones that break.
What are the foundational event-driven AI automation patterns?
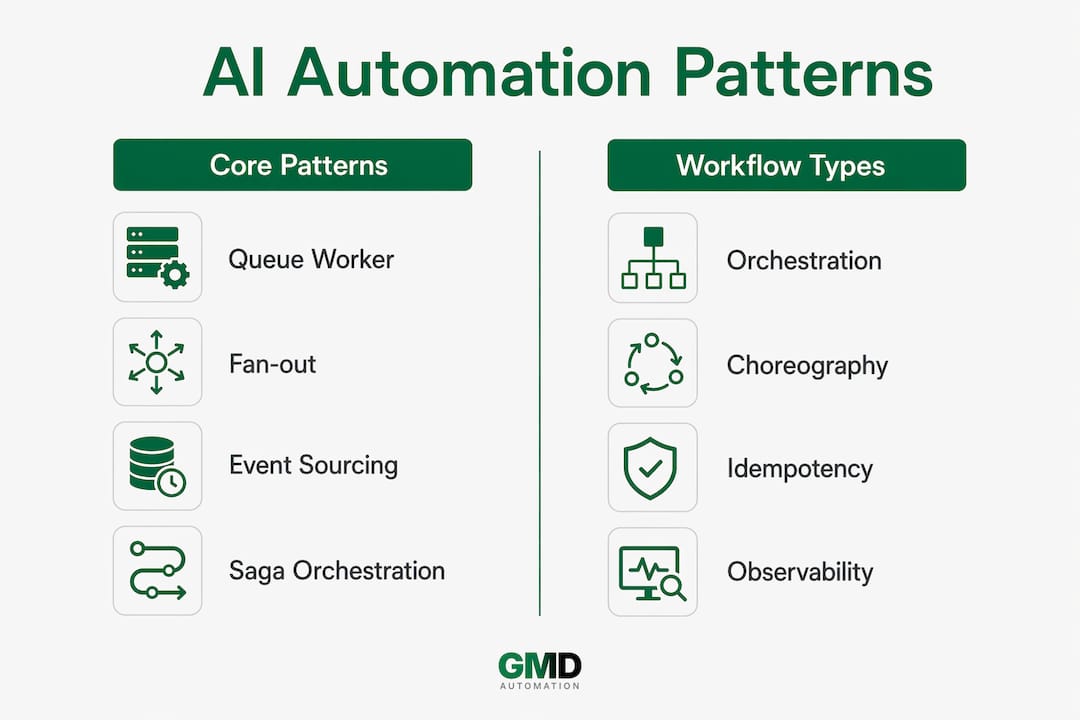
Production AI systems combine four core architectural patterns to achieve scalability, auditability, and reliable workflows. Each pattern solves a distinct problem, and knowing when to apply each one is what separates a well-designed event-based AI framework from a fragile prototype.
Queue with worker agents is the starting point for most implementations. A message queue such as Apache Kafka or Google Pub/Sub holds incoming events; a worker agent dequeues one event, processes it, and acknowledges completion before moving to the next. This pattern is straightforward to reason about, easy to monitor, and the right choice when sequential processing is acceptable.
Fan-out processing extends the queue model by routing a single event to multiple agents simultaneously. When an order is placed, one agent updates inventory, a second triggers a fulfilment workflow, and a third notifies the customer, all in parallel. The throughput gains are significant, but fan-out introduces coordination complexity that requires careful observability from the outset.
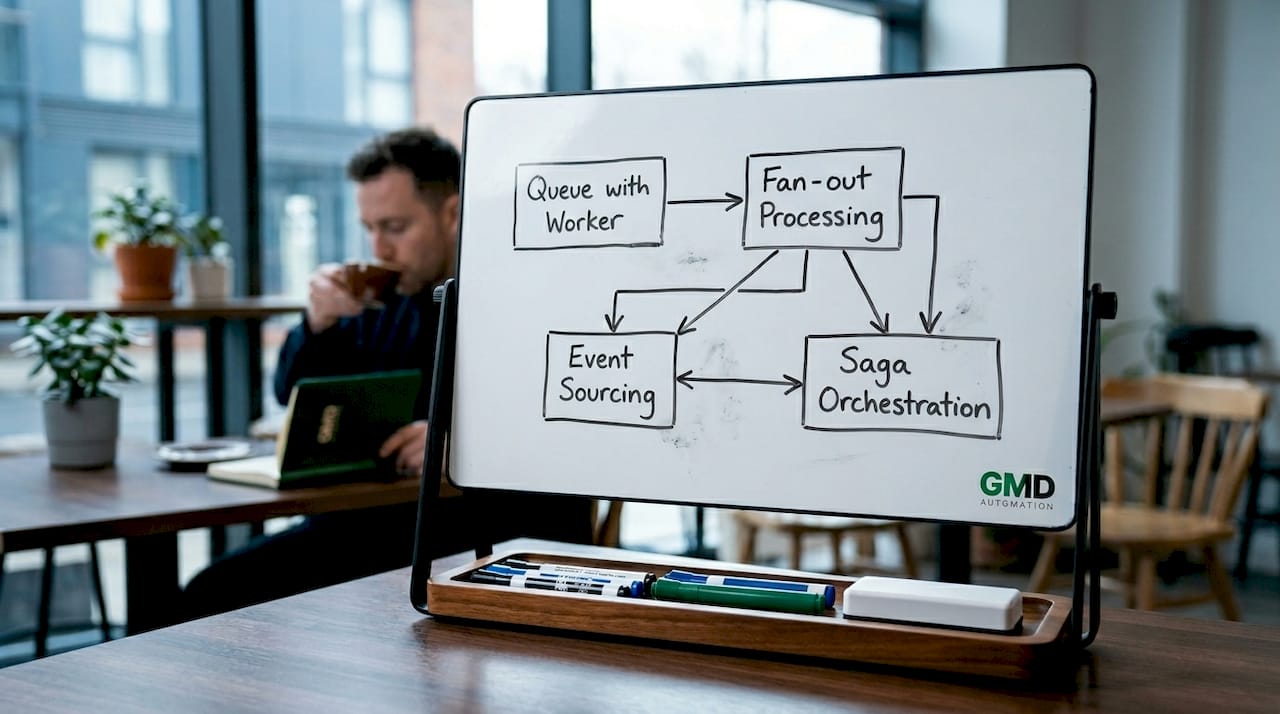
Event sourcing stores every meaningful state change as an immutable event record rather than overwriting current state. This gives you a complete audit trail and the ability to replay events deterministically, which is critical for regulated industries where AI decisions must be traceable and reproducible. Recording large language model (LLM) outputs as events also isolates their inherent non-determinism from the rest of your system state.
Saga orchestration manages multi-step workflows where individual steps can fail and must be compensated. Rather than a single atomic transaction spanning multiple services, a saga breaks the workflow into a sequence of local transactions, each with a defined rollback action. This is the pattern to reach for when your AI automation involves human approval steps, third-party API calls, or complex branching logic.
| Pattern | Best suited for | Key trade-off |
|---|---|---|
| Queue with worker | Sequential, single-event processing | Simplicity vs. throughput |
| Fan-out | Parallel multi-agent processing | Speed vs. coordination overhead |
| Event sourcing | Audit trails, regulated workflows | Storage cost vs. replayability |
| Saga orchestration | Multi-step, failure-prone workflows | Control vs. operational complexity |
What technical prerequisites must you address before deploying?
The most common reason event-driven AI deployments fail in production is not a flawed pattern choice. It is inadequate groundwork in validation, idempotency, and observability. Address these before a single AI model is invoked.
Event validation, deduplication, and rate limiting are the first line of defence. Every event entering your pipeline should be validated against a schema, checked against a deduplication window (Google recommends approximately 32 days for Pub/Sub), and subject to rate limits that prevent a sudden burst of events from overwhelming downstream agents. Skipping this step creates event storms that cascade through your entire system.
Idempotency is equally non-negotiable. LLM outputs are non-deterministic, which means that if an agent processes the same event twice due to at-least-once delivery semantics, you cannot guarantee the same decision will be produced. The solution is to store the event ID and the AI decision atomically in a single write operation, so that any retry simply reads the cached decision rather than re-invoking the model.
Observability deserves the same architectural priority as the business logic itself. Correlated logging and distributed tracing with correlation IDs allow you to follow a single event through a fan-out chain involving five or more agents. Without this, debugging a production incident becomes an exercise in guesswork. Structured logging, dead letter queues for failed events, and end-to-end tracing tools are the minimum viable observability stack for any real-time AI system.
Google Cloud's reference architecture illustrates these principles concretely. BigQuery continuous queries detect anomalies, Pub/Sub routes events with Single Message Transforms, and Vertex AI Agent Engine handles autonomous investigation. Each layer has a defined responsibility, and the boundaries between them are enforced by the event contract.
Pro Tip: Before writing any agent logic, define your event schema and deduplication strategy. Retrofitting idempotency into a live system is significantly more costly than building it in from the start. Treat your event pipeline design as a reliability contract, not an afterthought.
Saga orchestration vs. choreography: which fits your workflows?
The choice between saga orchestration and choreography is one of the most consequential architectural decisions in event-driven software architecture. Both manage multi-step workflows, but they distribute control very differently.
In orchestration, a central coordinator service directs each step, waits for confirmation, handles retries, and triggers compensating transactions on failure. This gives you a single place to inspect workflow state, set timeout policies, and add human-in-the-loop approval gates. Orchestrators handle retry and timeout logic explicitly, which makes them the right choice for complex branching workflows or any process that involves a human decision point.
In choreography, each service listens for events and reacts independently, with no central coordinator. A payment service emits a "payment confirmed" event; a fulfilment service listens for that event and emits "order dispatched." The system is truly decoupled and scales horizontally with minimal bottlenecks. The cost is that workflow state is implicit and spread across multiple services, making compensation logic and debugging considerably harder.
| Approach | Strengths | Weaknesses |
|---|---|---|
| Orchestration | Centralised visibility, explicit retries, human steps | Single point of failure, higher operational complexity |
| Choreography | True decoupling, high throughput, independent scaling | Implicit state, harder debugging, complex compensation |
The practical guidance is straightforward. Use orchestration when your workflow has more than four steps, involves conditional branching, or requires human approval. Use choreography for high-throughput, well-defined pipelines where each step is simple and failures are rare. Many mature systems use a hybrid: choreography for the high-volume outer loop and orchestration for the complex inner workflows that require governance.
Pro Tip: The choice between orchestration and choreography should be driven by your failure-mode visibility requirements, not by a preference for loose coupling. If you cannot afford to lose sight of where a workflow is at any given moment, orchestration is the safer default.
How to implement event-driven AI automation without common pitfalls
The most reliable path to a production-grade implementation follows a deliberate progression rather than attempting to deploy all patterns simultaneously.
-
Start with queue and worker. Deploy a single message queue and one worker agent. Validate that your event schema is stable, your deduplication logic works, and your agent acknowledges events correctly before adding any further complexity. This baseline also gives you a performance benchmark.
-
Add fan-out incrementally. Once the queue and worker pattern is stable, introduce parallel processing for events that genuinely benefit from it. Assign correlation IDs at this stage so that every downstream agent action can be traced back to the originating event.
-
Introduce event sourcing for regulated workflows. If your use case involves financial decisions, compliance obligations, or any scenario where an auditor may ask "why did the system do that?", implement event sourcing before going live. Rebuilding state via deterministic replay is far easier when the event log has been clean from day one.
-
Layer in saga orchestration for complex processes. Add orchestration only when your workflow genuinely requires multi-step coordination with failure compensation. Premature orchestration adds overhead without benefit.
-
Implement monitoring and fallback strategies. Dead letter queues capture events that fail after the maximum number of retries. Multi-agent parallelism requires correlated event IDs to diagnose timing and replay issues. Alerting on dead letter queue depth is one of the most useful early warning signals available to an operations team.
The most common mistakes in real-world deployments are wiring an AI agent directly to a high-volume event stream without validation, omitting deduplication and then discovering duplicate side effects in production, and treating observability as a post-launch concern. Each of these is recoverable, but each is also entirely avoidable.
"Treat the event pipeline primarily as a reliability system. The AI logic is only as trustworthy as the infrastructure delivering events to it."
Event-driven AI transforms manual bottlenecks by embedding intelligence directly into data streams, but that intelligence is worthless if the stream itself is unreliable. Governance of the pipeline is not a secondary concern. It is the foundation.
Key takeaways
Event-driven AI automation patterns succeed when reliability infrastructure, not AI logic, is treated as the primary architectural concern.
| Point | Details |
|---|---|
| Start with queue and worker | Build the simplest pattern first and validate reliability before adding fan-out or orchestration. |
| Idempotency is non-negotiable | Store event IDs and AI decisions atomically to prevent duplicate processing from non-deterministic models. |
| Observability from day one | Assign correlation IDs at the fan-out stage and monitor dead letter queues as a leading indicator of pipeline health. |
| Match pattern to workflow complexity | Use orchestration for complex, branching, or human-gated workflows; use choreography for high-throughput, simple pipelines. |
| Govern the pipeline first | Validation, deduplication, and rate limiting must be in place before any AI model is invoked in production. |
Why reliability must come before intelligence
I have seen organisations invest heavily in sophisticated AI models and then wire them directly to a raw event stream with no validation layer. The result is always the same: duplicate decisions, cascading failures, and a loss of confidence in the entire programme that takes months to rebuild.
The counterintuitive truth about event-driven AI automation is that the AI component is rarely the hard part. The hard part is building a pipeline that delivers events exactly once, in the right order, with enough context for the agent to act correctly. Get that right and the AI layer becomes almost interchangeable. Get it wrong and no amount of model sophistication will save you.
My strong recommendation to any IT leader planning a rollout is to treat AI agent architecture decisions as infrastructure decisions, not software decisions. That means involving your reliability engineers from the first design session, not after the first production incident. It also means building human-in-the-loop checkpoints into your saga workflows from the start, even if you intend to automate them later. The governance habit is easier to relax than it is to introduce retrospectively.
The patterns covered in this article are not theoretical. They are in production at organisations running billions of events per day. The difference between those that succeed and those that struggle is almost always discipline in the foundational layer, not sophistication in the AI layer.
— Ravi
How Gmdautomation helps you deploy these patterns
Gmdautomation specialises in deploying enterprise-grade event-driven AI systems for UK businesses, covering everything from initial event schema design through to production monitoring and ongoing optimisation. Their subscription model means you get a fully architected system, including validation, deduplication, idempotency controls, and observability tooling, without capital expenditure or a lengthy procurement cycle. Whether you are starting with a simple queue and worker deployment or need saga orchestration for a regulated workflow, Gmdautomation's team handles the reliability infrastructure so your team can focus on the business logic. Explore the full range of AI automation solutions and see how quickly a production-ready system can be operational for your organisation.
FAQ
What are event-driven AI automation patterns?
Event-driven AI automation patterns are architectural designs that trigger AI agent actions in response to discrete events such as transactions, form submissions, or sensor readings, rather than on a fixed schedule. Core patterns include queue with worker, fan-out, event sourcing, and saga orchestration.
Why is idempotency critical in event-driven AI systems?
Because message queues deliver events at least once, an agent may process the same event multiple times. Storing the event ID and AI decision atomically prevents duplicate side effects and ensures consistency despite the non-deterministic nature of LLM outputs.
When should you use saga orchestration over choreography?
Use saga orchestration when your workflow has complex branching, more than four steps, or requires human approval gates. Choreography is the better choice for high-throughput, simple pipelines where each service step is well-defined and failures are infrequent.
What observability tools are needed for event-driven AI?
Correlation IDs, distributed tracing, structured logging, and dead letter queues are the minimum requirements. Correlated event and run IDs are particularly important for diagnosing timing and replay issues in multi-agent fan-out architectures.
How do you prevent event storms in AI automation pipelines?
Validate, deduplicate, and rate-limit every event at the point of ingestion before it reaches any AI agent. A deduplication window of approximately 32 days, combined with schema validation and per-source rate limits, prevents the cascading failures that event storms cause.